




By Thomas Bohm
1. Introduction
Incorrect recognition of a letter or symbol can occur in a number of different situations, whether it be an unclear typeface, reading a book or at long distance reading a road sign, to more serious instances, like medicine information leaflets or on a display in an aircraft. Different people (general, children, dyslexic, visually impaired, ageing) also have specific letter and symbol issues and requirements. Which letters and symbols are the most problematic and how are letters and symbols to be designed for maximum recognition clarity?
The word ‘legible’ used in this paper refers to typefaces which have well defined easily recognisable letters and symbols, which can be decoded easily and quickly, which are not overly stylistic in letterform design, typically typefaces used in the context of continuous reading, not script typefaces.
2. Confusing letters and symbols for general people
We define general people as aged between 13–45 years old, who do not have dyslexia or visual impairments.
The following letters can be easily confused as other characters: lowercase l (el) can be read as the number 1 or a capital I (i). The capital I (i) can be read as a lowercase l (el) or as a number 1. The number 1 can be read as a lowercase l (el), capital I (i), or number 7 (Figure 1).

Figure 1. Typefaces: Bucko and Sassoon Infant.
Regarding the uppercase I (i), from research and testing Smuc et al. (2007) found that because of ‘a very high possibility for confusion with i, +, 1, t, l, it is advised to add serifs for distinction on top and base’.
In research and testing of a typeface (Tern) for road signage Smuc et al. (2007), found that ‘a bent terminal (at the bottom of the lowercase l (el)) was of great importance to distinction.’ Beier and Larson (2010) found that ‘a tail at the bottom of the lowercase l (el) letter, more specifically a broader one, improved legibility’.
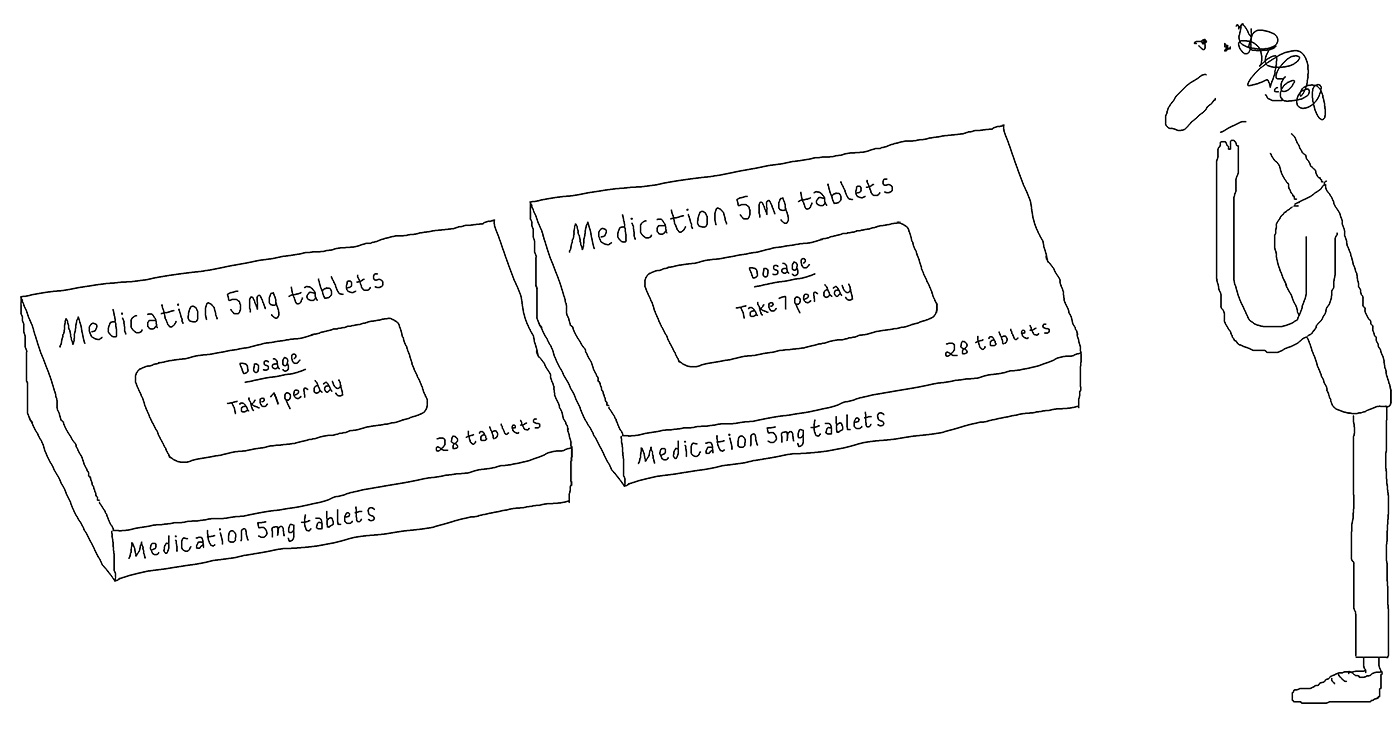
Also Smuc et al. (2007) found that ‘a distinctive arm (at the top of the number 1) has a positive effect on discrimination, serifs at the lower end of stem do not seem to have an influence’. This is something I would question: that serifs at the bottom of the number 1 do not have an influence on recognition and clarity. In Chaparro et al. (2011), a number 1 with a distinctive arm at the top and a serif at the bottom scored 97% identification in testing with users, whereas a number 1 with only a distinct arm at the top and no serif at the bottom scored 43%; there is conflicting research in this area, for me the number 1 with an arm at the top and serif at the bottom defines the number 1 the most obviously (Figure 2).

Figure 2. Typefaces: Mandatory, Century Gothic, Adobe Garamond, Myriad, Monaco, Verdana, Knockout, Century Gothic, DIN, Sassoon Infant Alt, and Rockwell.
In a fast (extended reading) or long distance (car number plate) reading environment, the lowercase i could be read as a lowercase j (Scarrott, 1968). The capital B could be read as the number 8, and the capital D as a number 0 (zero), capital O (ow), or lowercase o (ow) (Nicholson, 2007). Other potentially confusing letters in some typefaces are the italic lowercase k (which could be confused as an italic capital R), the italic lowercase a (which could be confused as a lowercase o (ow), capital O (ow) or 0 (zero)), italic capital J (Spencer, 1969) (which could be confused as a lowercase f), the italic lowercase r (which could be an italic lowercase v or capital Y), the German Eszett (ß) (which could be confused as a capital B or number 8) and the lowercase g (Banjanin et al., 2013) (which could be a lowercase q) (Figure 3).

Figure 3. Typefaces, line 1: Century Gothic, Trebuchet, line 2: Mandatory, Helvetica Neue Condensed, Georgia, line 3: Mandatory, Helvetica Neue Condensed, line 4: Georgia, line 5: Bembo, line 6: Myriad, line 7 and 8: Baskerville, line 9: Century Gothic, Adobe Garamond, Mandatory, line 10: Courier.
Smuc et al. (2007) found that ‘the negative space between the stem and the dot (space between dot on i and main stroke) must be wide to allow for good distinction from characters as l, f, I, 1, [...]. The influence of a serif is to be explored in further testing’. In research and testing Beier and Larson (2010) found that ‘the hypothesis that serifs on the letter “i” improve legibility was confirmed for distance viewing. [...] it seems as if the slab serif on top of the stem helps to clarify the letterforms, although when placed at the bottom, the character becomes difficult to identify’. However, the last point, that the serif on the bottom of the i makes the character difficult to identify, is something I would question.
Regarding the lowercase j, research and testing (Smuc et al., 2007) found that ‘the tail is needed to be considerably bent and wide’. Beier and Larson (2010) support this: ‘The hypothesis that broad characters improve legibility was confirmed overall for the letter “j” (larger tail, broader descender)’.
The United Kingdom car number plate in Figure 4 shows a letter which is not in a normal alphabet. What does it stand for? I have been unable to find out. From comments, Riccardo Sartori suggests it is a capital L rotated 180 degrees to form the letter/number which symbolises a number 7.

Figure 4. Letter on car number plate not in normal alphabet. Top typeface: English car number plate typeface ‘Mandatory’, bottom typeface: German car number plate typeface ‘FE-Schrift’.
Speech marks in typefaces like Verdana, Frutiger, Syntax (“ ” , ‘ ’) can be confused and look like prime marks (″ = inches, ′ = feet) or single and double dumb quotes (' , ") (Figure 5).
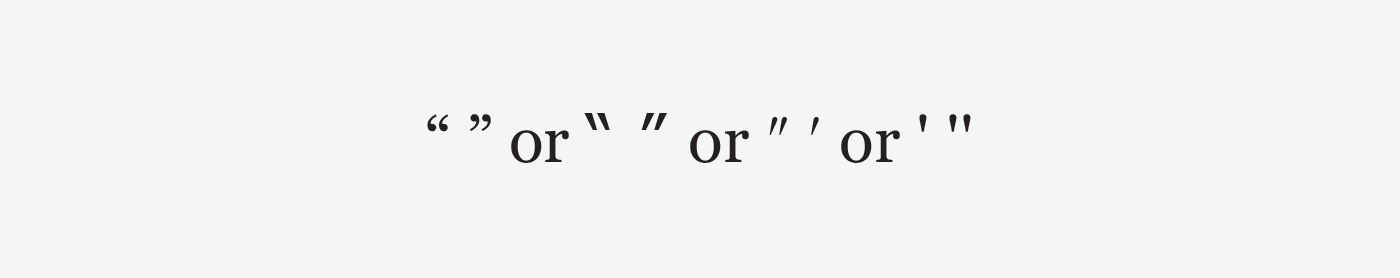
Figure 5. Real curly quotation marks, Verdana quotation marks, inch mark, feet mark, single and double dumb quote.
There are also three types of fraction marks (see image below). The third example could be read as a division sign. Whereas the second example uses a diagonal line which implies that the number above and below is a chunk, fraction of the numbers, a horizontal line has connections with division, dividing the number above and below, this is also supported by design of the division sign (÷) (Figure 6).
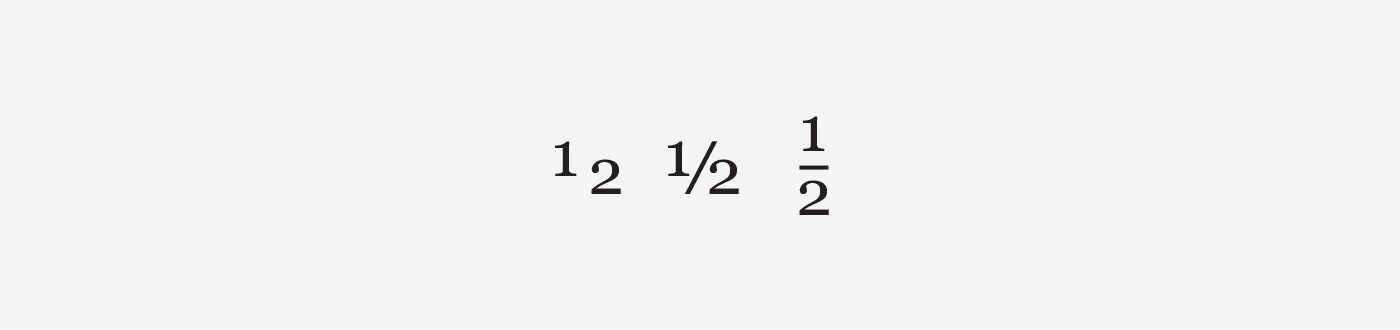
Figure 6. Fraction sign 1, 2 and 3.
Midpoints (·) should not be used as decimal points (.). I have seen midpoints used as decimal points in real life contexts: GCSE educational textbooks (Burndred, 1997) (Figure 7).

Figure 7. Midpoints and decimal points.
Why are commas used as decimal points when a decimal point is specific to numerical use? You would never write 2,5 mm, but you would write 2.5 mm. You would more often see 2 thousand 500 sheets written like so: 2,500 sheets, but rarely and maybe more correctly like so: 2.500 sheets. Commas should not be used as decimal points, as frequently seen in newspapers, because a comma marks a pause in text and is not specific to numbers. However, there are two co-existing conventions worldwide. One uses decimal points, the other uses decimal commas. More countries are subscribing to decimal commas than to decimal points. A decimal comma or decimal point can also be used to separate thousands, for example: English style: 967,295.00 (nine hundred and sixty seven thousand two hundred and ninety five pounds and zero pence), German style: 967.295,000 notice how the English and German styles are reversed. We can also note that in time values, a colon is used to separate hours, minutes and seconds. Note: if you use a space in numbers, it can split the numbers up, making them look like two different numbers. Figure 8.

Figure 8. Comma, decimal, and space points for numerical data (line 1). Thousands separator (lines 2 and 3), and colon for time data (line 4).
Roman numerals I, II, III, IV, V, VI, VII, VIII, IX, X (1–10) are a frequent source of confusion. Few people know their meaning. One should avoid using them. Also, a multiplication sign, an italic uppercase I (i), vertical line used as a separator used incorrectly, and the letter combination TT can also be misrecognized as a mathematical pi symbol. Figure 9.

Figure 9. Multiplication sign (line 1), italic uppercase I (i) vertical line and italic uppercase I (i) set in Century Gothic then Verdana (line 2), vertical line set in Helvetica (line 3), and TT and pi symbol (line 4).
‘Tightly spaced sans serif typefaces (Century Gothic, Helvetica) are more prone to confusion, because they do not have serifs which add definition to characters’ (Hudson, 2009).
Other confusing letter combinations are cl, which can be read as a lowercase d; rn, which can be read as a lowercase m; vv, which can be read as a lowercase w (Albert-Jan Pool, 2009); lowercase o (ow), capital O (ow), and 0 (zero), which can be read as each other. In OpenType typefaces, a defined (slashed or dotted) zero can be built into the typeface and selected from the typeface/software using the slashed zero option. The capital S could be read as 5, Z could be read as 2, LJ (capital el and jay) could be read as an uppercase U (as is noticeable in the professional dart player’s name MENSUR SULJOVIĆ). There is also the case of possibly needing to clarify the numbers 6 and 9 by adding an underline to them to mark where the baseline of the number is, in order to tell what number it is and if it has been turned around, like you see when lottery balls are being extracted from a tumbler on TV or on pool balls. There is also the case that a helicopter could need to identify the number on the top of a car’s roof on an official vehicle or ambulance. ce (when tracked/letterspaced tightly) can be seen as a œ (diphthong). Dmytro Perepølkin a data scientist from Norway contacted me via email in 2018. He raised an interesting issue regarding letter and symbol misrecognition used for phishing and spoofing purposes. Phishing is creating a fake lookalike page of a specific page. Spoofing can be defined as duplicating a domain name/phone number/email address/IP and using it for wrong purposes. See Figure 10 for an example of what he was suggesting. Even though characters in domain names between the www. and .extension are closely standardized, it is still a possibility that problems from letter and symbol misrecognition in domain names and URLs could be used for illegal purposes. Figure 10 and 11.

Figure 10. Easily misrecognised letter combinations for general people. Typefaces: Century Gothic, Cambria and Myriad.

Figure 11. Typefaces: Trebuchet, Monaco, Andale Mono and FE-Schrift.
Situations in which the previously described letters and symbols could get misrecognised are as follows:
- III or Ill: Academic book.
- Number 1 or 7: Medicine information leaflet, road signage, financial data.
- i or j, B or 8, D, O or 0: Text (book), long distance (car number plate).
- Apostrophe/speech marks: Text, mathematical work.
- Fraction sign: Academic/educational textbook.
- Decimal point (.)/midpoint (·): Academic/educational textbook.
- Decimal point (. or ,): No major confusion, but possibly in financial data, a newspaper or academic text.
- Multiplication sign: Academic/educational textbook.
- Letter combinations: Text or signage.
- Number 0 (zero), lowercase o (ow), capital O (ow): username and passwords for online accounts, international zip/postal codes (Chaparro, et al., 2006), aircraft monitors (BBC News, 2002), credit card number or speed cameras.
3. Confusing letters and symbols in condensed typefaces and superscripts/subscripts
Some condensed weight typefaces work and read as good as regular weight typefaces. However, in highly legible condensed typefaces, the condensed nature and form of letters does not give the letters the normal horizontal width they need, which creates specific problems, especially when they are used either very small, less than an x-height of 1.5mm (around 8pt) or less, or at long distance on signage or car number plates. Also if you look at the default superscript and subscript for the number 1 in a typeface like Calibre, unfortunately the typeface does not offer an alternate design to the default number 1 used specifically for superscripts or subscripts. The default number 1 style for superscripts and subscripts has an arm on the top, but no stroke on the bottom. You cannot input the default number 1 style used for the number 1 in general body text (which does by default have an arm at the top and stroke on the bottom of the number 1). The result of this is that, the number 1 in the superscript or subscript without a stroke on the bottom, could be seen as a small number 7. Why might the typeface designer have not provided an alternative number 1 style for superscripts and subscripts in Calibre? Maybe the typeface designer feels a stroke on the bottom, at the typically small size superscripts and subscripts are, would hamper legibility. What do non expert typographic people think of this, is it unclear or does it create confusion for general readers and the public? (Figure 12).
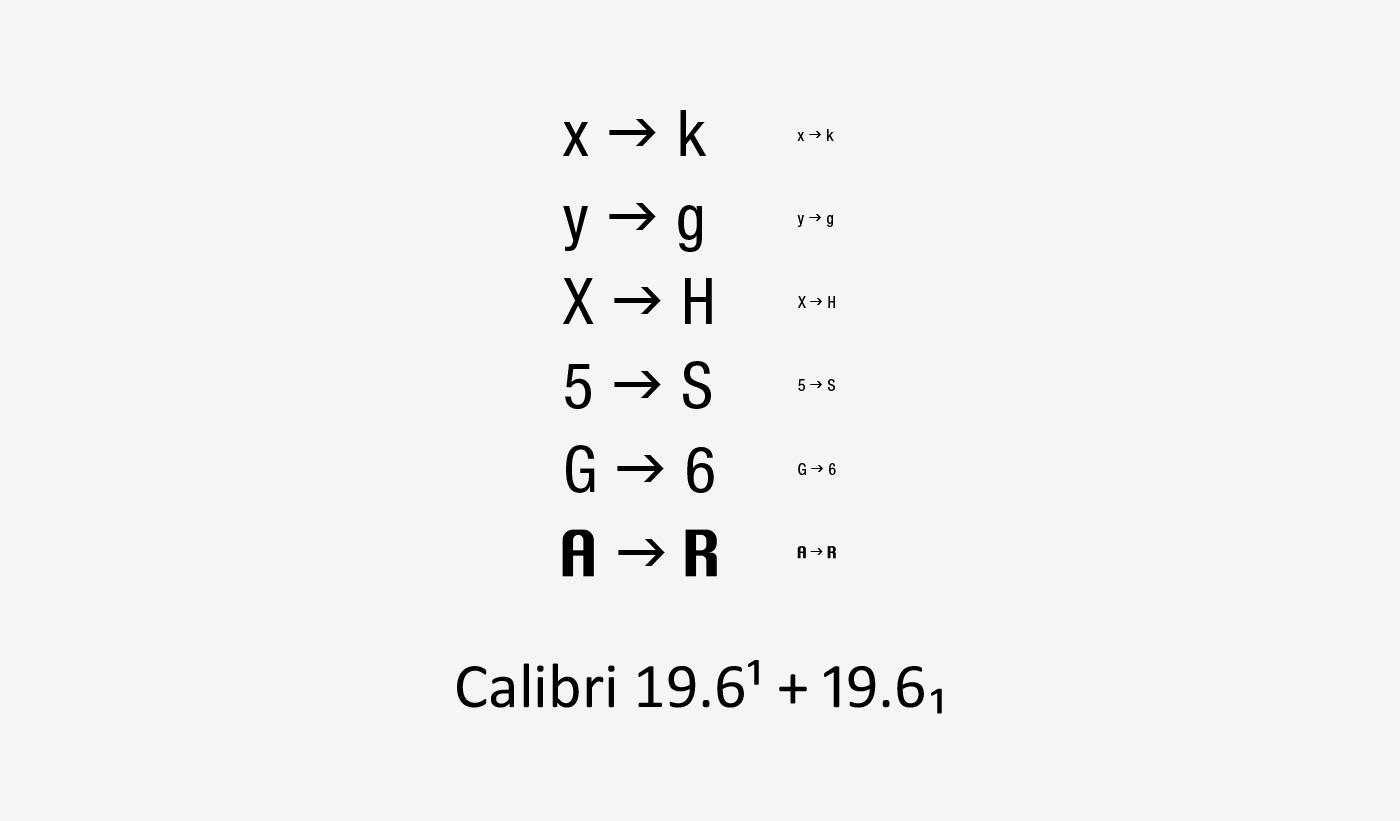
Figure 12. Examples showing condensed weight issues, and the superscript and subscript number 1 designs in the typeface: Calibri. The number 1 design for superscripts and subscripts is unchangeable and does not match the default number 1 design. Typefaces: Helvetica Neue Condensed, Silom and Calibre.
4. Confusing letters and symbols for children
We define children as aged between 4–12 years old.
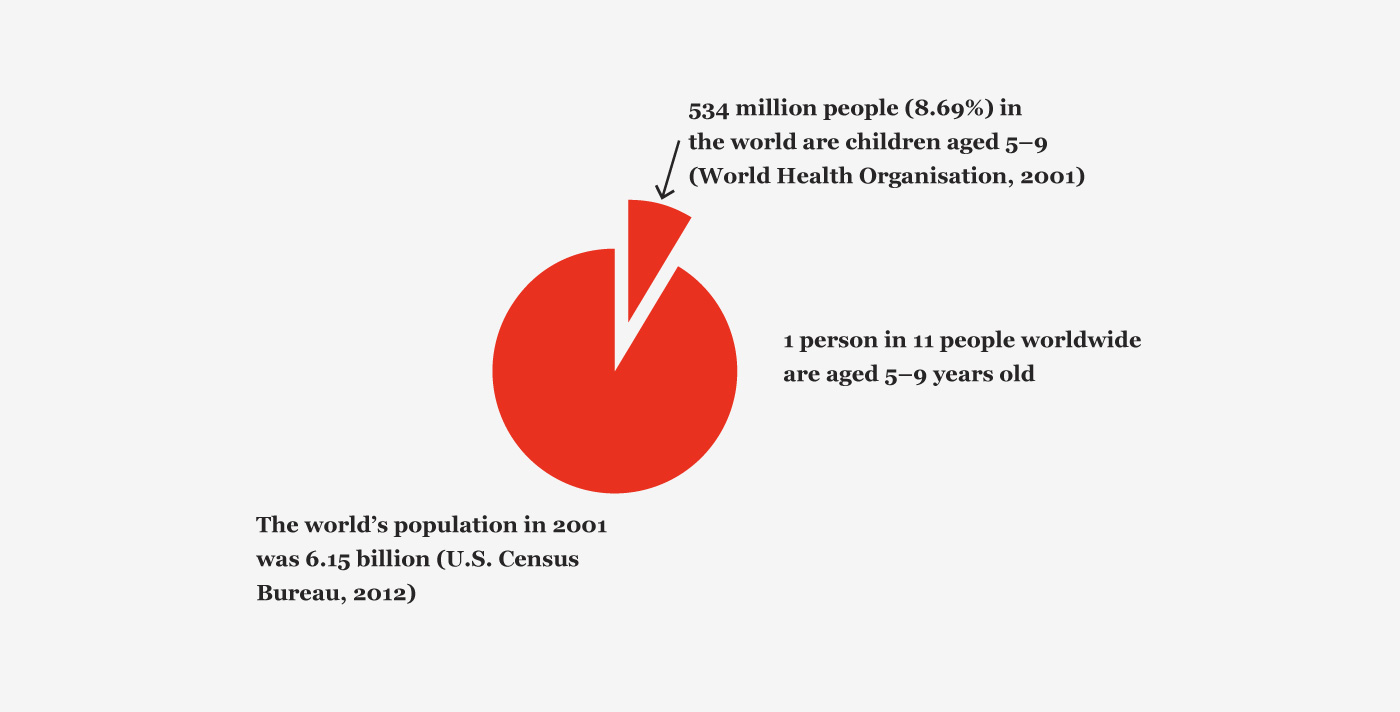
Figure 13. Population of people who are children.
Infant characters, a, g, l, q, y, I, J, 1, 4, 7, 9, are characters specifically designed for people around 6 years old. In research and testing (Walker, 2005), ‘a possible reason for using infant characters is to make the characters more like handwritten forms’. Infant characters are what a child aged around 6 years old would write (by hand) and would be taught to write; subsequently, infant characters might more clearly reflect what they do and are taught. When children are a few years older and have learned to read and write fairly confidently, there is less need to use infant characters as a clarification. However, in the results from testing (Walker, 2005), infant characters did ‘not affect their reading performance in our tests’ and the children were able to point out ‘[an infant a] is what we write, [a normal a] is what we read’.
In research and testing (likely to be adult people), Beier and Larson (2010) found that ‘the infant a resulted in bad performance and misreadings’. Although as Sassoon (2001) points out, ‘recognition is a dominant factor when learning to read; the fact that the one-storey (infant) a, references to the letter shape that most children learn to write, has a positive influence on the inexperienced reader’. What can be noted is that the tail (stroke to the bottom right of the character of the infant a) in the typeface Sassoon Infant is far greater and defined than the infant a in a typeface like Century Gothic and many others.
Infant a’s are also used in italic and cursive typefaces; they present the same misrecognition problems as normal infant a’s.
In contemporary advertising/graphic communication typography in the United Kingdom, the infant a character is increasingly becoming popular (Age UK, Churchill Insurance, Facebook, Mastercard, Royal National Institute for the Blind, Vodafone, Waitrose, Waterstones, Yellow Pages), although the obvious problem is that it looks very similar to the lowercase o (ow) or a (0) zero or an uppercase O (ow) or even a lowercase sans serif Greek Alpha letter in an academic context [serif lowercase Greek Alpha letters seem to be in general more defined/distinguished than sans serif versions], a similarity which is increased further in a continuous reading context, [what is Mostercord?]. This increase in the popularity of the infant a is a typeface design fashion around the year 2011 (Figure 14 and 15).

Figure 14. Infant a’s in contemporary logo designs.

Figure 15. Infant a, lowercase o (ow), 0 (zero), captial O (ow) italic a, and lowercase Greek Alpha letter (sans serif), and lowercase Greek Alpha letter (serif, in brackets). Typefaces: Century Gothic, Georgia Italic, Myriad and Georgia.
Characteristics of infant characters are a: single story, g: single descender without loop, l: tail at bottom, q: diagonal line on descender, y: more curved descender, I: stroke on top and bottom, J: stroke on top, 1: diagonal stroke on top, 4: unjoined top, 7: crossbar on stroke, and 9: straight stem (Figure 16).

Figure 16. Top: Infant characters, bottom: normal characters. Typefaces: Above: Sassoon Infant, Below: Helvetica Neue, Trebuchet, Mandatory.
5. Confusing letters and symbols for people with dyslexia
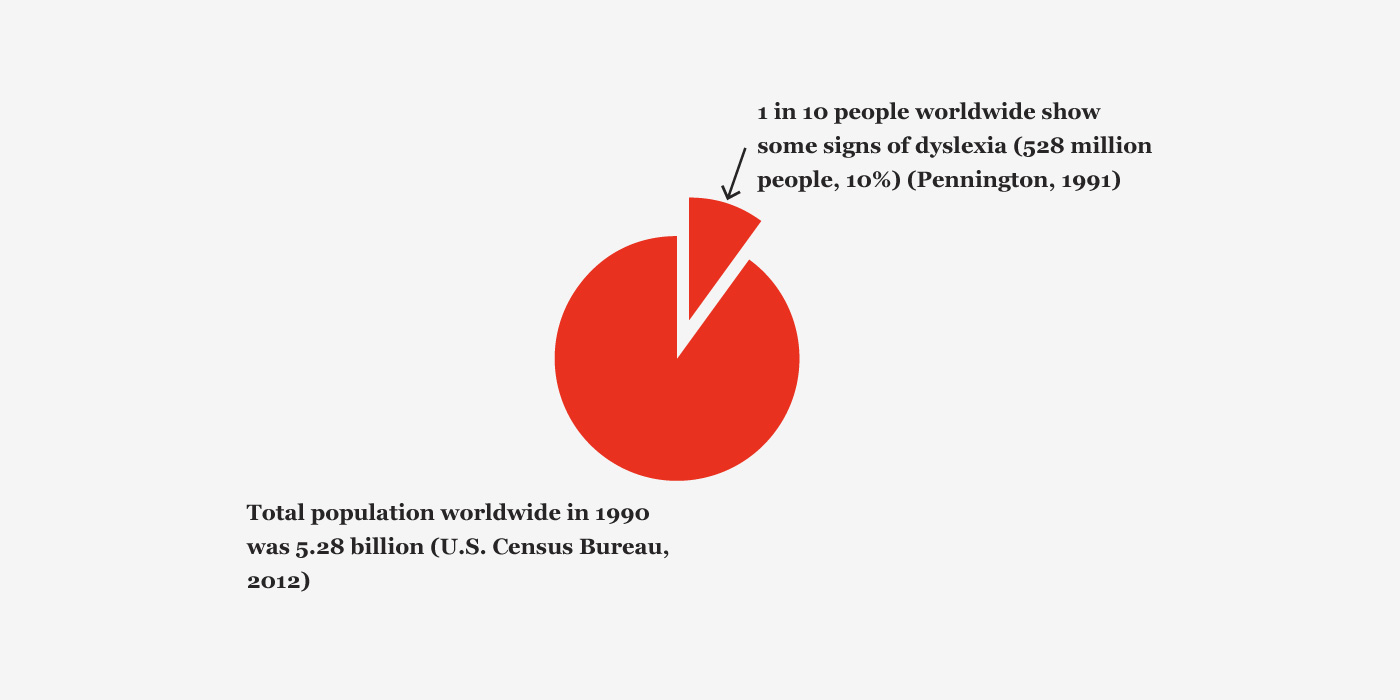
Figure 17. Population of people with dyslexia.
Dyslexia is a neurologically-based, often familial disorder which interferes with the acquisition and processing of language. Varying in degrees of severity, it is manifested by difficulties in receptive and expressive language, including phonological processing, in reading, writing, spelling, handwriting, and sometimes arithmetic (Bright Solutions for Dyslexia, 2010). However, ‘the condition covers as many difficulties with the spoken and written word as it does definitions’ (Hillier, 2006).
From research and user testing (Hillier, 2006), ‘dyslexic users encounter identification problems with the following characters: lowercase l, numerical 1, exclamation mark !, lowercase o; uppercase O, p q, b d, j g, m n, m w, g h t, J L, L I. Character confusion difficulties are experienced with the following characters: b/d, p/q, a/e, b/k, u/v and the numerals. All of these difficulties are related to the similarity in design of the character forms, resulting (in the examples of b/d, p/q and 6/9) in letter reversals. Vowel letters (in the example of a/e) may also be a factor in dyslexic character confusion’.
Hillier (2006) from research and testing found that people with dyslexia prefer the following:
- Handwritten style letters.
- Uppercase (Sylexiad) forms rather than lowercase forms.
- Long ascenders and descenders. [Height of the letters which go above and below, for instance, a lowercase x].
- Distinctive and well-defined letters. [Not typefaces such as Arial, Century Gothic, Futura, Helvetica, which have very similar, undefined, geometric rounded forms].
- Uniform stroke widths. [Not a typeface such as Times New Roman, which has varying stroke widths].
- Perpendicular design. [At an angle of 90° to a line or surface, upright, vertical].
- Familiarity of form.
- Sylexiad Serif (as a typeface family) (Figure 18).

Figure 18. Robert Hillier, typeface: Sylexiad Serif Medium Regular and Italic weights (sans serif version also available).
In 2008, Christian Boer (Boer, 2008) designed a typeface called Dyslexie to increase the accuracy and readability of texts for dyslexics so that the errors by switching letters are reduced. Renske de Leeuw (de Leeuw, 2010) researched and tested the typeface. They found that Dyslexie resulted in fewer reading errors, although mainly in the specific area of dyslexics switching, flipping, mirroring and turning letters, such as the p and d (de Leeuw, 2010). Their main implemented design features considered to be of benefit to dyslexic readers are:
- Keeping the focus on the letters at the bottom.
- Enlarging the openings (counters) of the letters.
- Making some letters a bit italic.
- Defining characters which look quite similar.
- Making the sticks (ascenders and descenders) of some letters longer.
- Making the capitals and the punctuation bold at the beginning and the end of the sentence.
- Making similar looking letters different heights, each with its own features.
- Using wider letterspacing than is normal (Figure 19).

Figure 19. Christian Boer, typeface: Dyslexie Regular and Italic.
6. Confusing letters and symbols for people with visual impairments
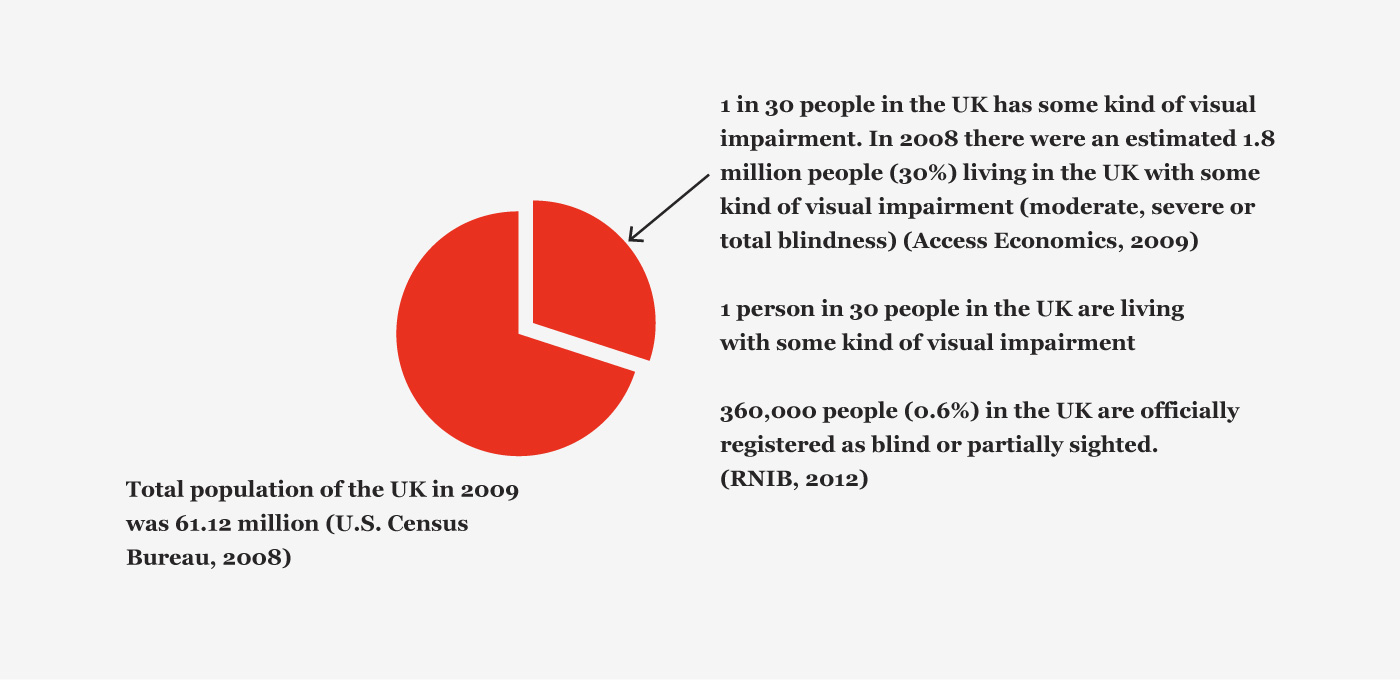
Figure 20. Population of people with visual impairments.
The 2 million people with a sight problem in the United Kingdom have varying degrees of sight loss, ranging from those who have no light perception at all (total blindness), to those who have a sight loss which is uncorrectable by aids such as glasses and who have difficulty reading small print as well as text at a distance.
The many different eye conditions affect people in different ways. Three common eye conditions are glaucoma, diabetic retinopathy, and macular degeneration (Figure 21). Glaucoma can result in tunnel vision, where all side vision is lost and only central vision remains. Diabetic retinopathy can cause blurred and patchy vision. Macular degeneration can lead to a loss of central vision while side vision remains. But everyone is affected in different ways, and it is important not to assume that you know what someone can see simply because you know which eye condition she/he has (RNIB, 2006). The vast majority of people with sight problems are aged 65 and over (Tiresias, 2009). Another common term which gets used also within the area of visual impairments is low vision, low vision is defined as visual impairments that are not correctable through surgery, pharmaceuticals, glasses or contact lenses (The Vision Council, 2015).

Figure 21. Three common eye conditions. Photo credit: Action for Blind People.
People with visual impairments are likely, due to similarity of form, to find the following letters hard to recognise and confusing due to lack of visual clarity. The number 1, capital I (i) or lowercase l (el) or exclamation mark; the capital U or capital V; the lowercase u or v; number 5 or capital S; capital B and number 8; lowercase (infant) a or lowercase o (ow) or number 0 (zero) or uppercase O (ow); capital D or number 0 (zero) or uppercase O (ow) or lowercase o (ow); lowercase i and j; cl or d; rn or m; vv or w; capital Z or number 2; capital C or G; capital Q or uppercase O (ow); capital I S and O (ow) or number 150; word go or number 90 (using oldstyle figures). The letter combinations: LJ (capital el and lowercase jay), IJ (capital i and jay) LI (capital el and i) Ll (capital el and lowercase el) L1 (capital el and number 1) could be seen as an uppercase U. The letter combinations: LU (capital el and u), LLI (capital el el and i), LILI (capital el i el and i), and UU (capital u) could be seen as an uppercase W [other problematic characters which could be substituted into this previous series are the lowercase l (el) and number 1]. The following letter combinations: LU, LLI, UU could be read as an uppercase W, and LILI as UU [other problematic characters which could be substituted into this previous series are the lowercase l (el) and number 1]. The letter combinations: CI (capital c and i) can be seen as an uppercase O (ow) or number 0 (zero) [other problematic characters which could be substituted into this previous series are the lowercase l (el) and number 1]. There are also issues to do with letter design and punctuation/symbol combinations: <J (less than symbol with an uppercase jay) can combine to look like a <l (lowercase el) or <I (uppercase i). A lowercase or uppercase j to the right of a starting bracket/parentheses: (J (j could possibly look like an uppercase U, Peter Glaab (Glaab, 2017) has mentioned that a small white space character or extra kerning is manually necessary. Another similar problematic letter combination is: (T (which can look like a uppercase N). Figure 22.

Figure 22. Easily misrecognised letter combinations for people with visual impairments [and people with ageing eyesight, see heading number 7 later on in this paper]. Typefaces: Century Gothic, Myriad. Line 20 (last): Calibri, Lucida Sans, Avenir.
A recent example of one of the previous issues becoming a real-life problem was from an article by Ewout van Lambalgen (van Lambalgen, 2017). Ewout and a friend of his (both did not even have any visual impairments) booked their flight and then tried to check-in for their flight via an app on their mobile phone. The app kept on giving errors without being specific about what was going wrong. He then moved from a mobile app to a website, where he got an error message telling him that he apparently entered his friend’s passport document number incorrectly. The issue was all down to bad typography. The passport number was written like so: S35P7EC8 using capital letters and oldstyle figures. Because she was not paying enough attention and does not have a lot of knowledge about typography, she did not notice that the B in her document number (she misrecognised the last number eight as a capital B) was actually an 8 (number eight) due to the number eight aligning/sitting on the baseline and not dropping below the baseline (Figure 22.2).

Figure 22.2. Typeface: Calibri.
Additional guidelines (Perera, 2001) regarding letter design for people with visual impairments are as follows:
- Anything in italics is very difficult for partially sighted people to read.
- Sans serif or bracketed serif was preferred over serif. It appears that a slight degree of serif which accentuates the characters ends without distracting from the simple form actually increased legibility.
- Normal or enlarged spacing. [This refers to spaces between characters (tracking/letterspacing)].
- Darkest weight/bold letters.
- Punctuation marks should be made bigger, but not to the point where they distract from the content (Figure 23).

Figure 23. Tiresias LPfont: Regular and Italic weights (Perera, 2001). Illustration (right) slight degree of serif on characters in LPfont (LPfont stands for Large Print font).
7. Confusing letters and symbols for people who are ageing
Ageing people are aged 45+ years old and may have started to develop impaired vision.

Figure 24. Population of people who are ageing.
The population of the UK is ageing, the percentage of the population aged 65 and over increased from 15% in 1984 to 16% in 2009, an increase of 1.7 million people. This trend is projected to continue. By 2034, 23% of the UK population is projected to be aged 65 and over (Office for National Statistics, 2010). 28% of the world’s population between the years of 2000–2025 will be aged 45 and older (World Health Organisation, 2001).
Brad Pettengill outlines 3 common conditions of ageing eyesight (Pettengill, 2014):
- Loss of light: advancing age causes the pupils to shrink, less light enters the eye, causing vision problems in low-light environments.
- Inability to focus: the eye’s lens loses elasticity, becomes less able to focus while reading.
- Vision field loss: age-related eye diseases include macular degeneration, glaucoma, cataracts and diabetic retinopathy.
Due to lack of visual clarity (blurred, dark), which can also be known as presbyopia (Funcke, 2002), people who are ageing are likely to experience problems with the same letters and symbols described under heading: 6. Confusing letters and symbols for people with visual impairments mentioned earlier in this paper. Additional guidelines (Nini, 2006) are as follows:
- Consistent stroke widths [not typefaces like Bodoni or Times New Roman].
- Open counter forms.
- Pronounced ascenders and descenders.
- Wider horizontal proportions.
- More distinct forms for each character (such as tails on the lowercase letters ‘t’ and ‘j’).
- Extended horizontal strokes for certain letterforms (such as the arm of the lowercase letter ‘r’ or the crossbar of the lowercase letter ‘t’).
8. How do we and should we test typefaces?
We can research and theorise all we like, but a good evaluation is surely by finding out if our intentions are experienced by people, and even to learn about new problems and what is or is not working. What can we test in regard to a typeface? Alex Poole (Poole, 2012) suggests these measures of legibility or readability:
- Speed of reading.
- Speed of perception.
- Fatigue in reading.
- Backtracking and other eye movements.
- Perceptibility at a distance.
- Perceptibility in peripheral vision.
Other measures to add to the mix could be:
- Personal preference.
- Ideal and best maximum optimized performance for a certain user type and use task.
- Appeal.
- Recall: quality of comprehension understanding of the text.
- Motivation.
- Read aloud/back.
- Quality of rendering on screen and hinting issues (technical).
I am sure the lists above do not list all possibilities. It is worth noting that some of these testing options will get you weak information (like personal preference) and some will get you stronger information. Ruth Shrensky and David Sless (Shrensky & Sless, 2007) mention the following in regard to testing: ‘[...] The first is that inexperienced, untrained, or misguided information designers ask the wrong questions: What do people think of my designs? Which of my designs do they prefer? What must my artifact look like? What information must my artifact contain? The second reason is that asking the wrong questions about the design leads inevitably to certain ways of asking questions – methods of testing which give inadequate answers. [...]’. David Sless also raises the problems with: attitude and opinion surveys, preference tests, expert opinion and content-based design. ‘[...] A far more useful question to ask before you design a new information artifact or redesign an existing one is, what do I want people to be able to do with this artifact? [...]’. So we can observe that not all data or information gained is necessarily useful.
Ralf Herrmann mentions (Herrmann, 2011) in regard to testing typefaces generally: ‘Doing scientific studies to test which typefaces work best in this regard is almost impossible to do. For a proper test setup you would need to modify one parameter while keeping every other parameter unchanged. But setting a letter or word in different typefaces can not be considered as ‘changing one parameter’, because a typeface consists of dozens of relevant parameters like x-height, weight, contrast, width – just to name a few. So scientific test for typeface legibility are often full of flaws. Very often the typefaces are set at the same point size, but as every graphic designer should know, the point size does not reflect the actual size of the letters in print or on screen. So if you come across a scientific legibility study that compares typefaces set at the same point size, don’t even bother to read on!’.
9. Concluding observations
For general people, quite a few letters and symbols in highly legible typefaces are usually not defined enough, resulting in letter or symbol misrecognition, word confusion, and possibly fatal incidents. The context the letter/s or symbol/s is in, is also important, if the confusing letter or symbol is within a word you can probably work out what it is by looking at the whole word, if the confusing letter or symbol is isolated, on its own or within a password, it can be difficult to tell what it is. I came across quite a bit of research stating that, for instance, the lowercase y could be confused with the lowercase z (Grissinger, 2017) and the capital H and N could be confused with each other (Russell-Minda et al., 2007) and so on, which I was not convinced about. I cannot see how, if using a highly legible typeface for these characters, that they would ever get confused, so this information was not discussed further in this paper. I have noticed in 2019 that a version of Neue Frutiger called Neue Frutiger 1450 was released by Linotype in 2013 which tries to adhere and tackle issues raised in this paper and conform to DIN (Deutsches Institut für Normung) legibility standard 1450:2013-04 (DIN, 2013) which I have been unable to read because it is not in a language I am fluent in. It seems to make good commercial sense, as Frutiger is used a lot for signage and signs in airports. There is also the very real and present issue of webfonts, we have come to the point where basically any typeface designed recently or that is available in a digital format will most likely be use and can be used as a webfont. If a typeface is used as a webfont, the requirements and uses of the webfont, in regards to the information it will be required to handle, is strictly unpredictable and diverse. Finally, I noticed this billboard for a local historic attraction, see Figure 25, notice what they have done at the bottom of the billboard in the website address (all the typography for the billboard is capital letters), the website address should have been written like this: WWW.KRIII.COM but was written like this: WWW.KRiii.COM, I think this just reinforces that there is a genuine problem in this area in regard to typeface design.

Figure 25. An interesting issue is highlighted in the website address at the bottom of the billboard.
For children, the infant a is the most problematic character. It is easily misrecognised and, for some reason, has always been considered beneficial. This is not the case though. Research and testing reviewed in this paper has shown that even adults misrecognise the infant a. If the infant a character is used for children around 6 years old, it should be much better defined (like in the Sassoon Infant typeface) and used with caution. The infant a should not be used for competent, teenage, or adult readers. Where does this variation of standard recognizable letter shapes end? Also, infant a’s commonly used in italic or cursive typefaces should be well defined or distinct, or one should use a slanted form of the regular upright lowercase a. Is a reason for the rise in infant a’s because typefaces designers and designers want the text and typography to feel more friendly and informal? Do people even notice this change? It is worth noting that children today more readily encounter a wide range and vast variety of different letter designs, whether it be in the environment, on TV, using a computer, or through mobile devices. They encounter much more varied letterforms than in previous years.
Reviewed research has shown that people with dyslexia, in terms of the amount of problems, are the most problematic user group. Highly defined letters and symbols are desirable, to minimize misrecognition, misreading and mirroring of letters, symbols, and words. There are also other issues not specifically in regard to letter and symbol misrecognition which people with dyslexia experience such as: a wash-out effect, a river effect and a swirl effect (Irlen, 1991). All these effects cause the text to blur and jump, which results in visual confusion for the dyslexic reader (Evans, 2004). If you look in books or on the internet you can find examples of what it is like for people with dyslexia who experience these issues. Do specifically designed typefaces for people with dyslexia actually work?, one study by Chuck Bigelow (Bigelow, 2014) concludes that after surveying more than fifty scientific papers and books about dyslexia, he found no evidence that special dyslexia fonts confer statistically significant improvements in reading speed compared to standard, run-of-the-mill fonts. There seems to be conflicting views in this area, some say specific dyslexic typefaces make a difference and some say not. There seems to be conflicting views in this area, some say specific dyslexic typefaces make a difference and some say not, some have positive testing results, some not. Unfortunately there is an increasing amount of fonts/typefaces claimed to be designed specifically for people with dyslexia which are not convincing and do not supply any or an insufficient amount of: research references, problems faced or tried to tackle, and no information about testing procedures or results with people who have dyslexia. Dyslexic typefaces not included in this paper are: OpenDyslexic, EasyReading, Read Regular, Riona Moore’s dyslexia typeface and DysLex (which seems to be a similar typeface to Dyslexie). As of 2019, some new typefaces have appeared which tackle issues of vision impairment and dyslexia: Lexie Readable and Andika. These typefaces claim they tackle issues, but offer no research, original research or references to support the design or claims, and offer no feedback or testing information with people, this is a bit disappointing.
For people with visual impairments, lack of visual clarity means that letters and symbols of similar form need to be well defined. More research and testing is needed into the problems people with visual impairments encounter when reading text.
For people who are ageing, a blurry and dark vision means that letters and symbols of similar form need to be well defined. More research and testing is needed into the problems people who are ageing encounter when reading text.
For graphic communication/information designers, interesting typeface examples in relation to this research are as follows: Avance, Copperplate Gothic, Info Display, Lola, OCR-A, Rockwell, Unit and Zine Slab.
For typeface designers, implementing the research and guidelines into typeface designs can be seen as part of the creative challenge of designing a typeface and it is not an intention to make your job any harder. With the invention of OpenType, alternate letters and symbols to a defined version of the typeface can be built into and selected through the typeface/software using ‘stylistic sets’ option.
Regarding testing of typefaces with people, we need to better setup and compare typeface material when testing, and also get better (stronger) information/data when testing with people. Sofie Beier (Beier, 2016) touches upon the different issues and constraints designers and academics have faced in the past ‘To produce findings that are relevant for the practicing designer, scientists benefit from consulting designers in the development of the experiments. While designers can contribute with design skills, they cannot always contribute with scientific rigor. Hence, researchers will profit from adopting a methodological approach that ensures both control of critical typographical variables and scientific validation. An interdisciplinary collaboration where scientists provide valid test methods and analysis and designers identify relevant research questions and develop test materials, will enable a project to reach more informed findings than what the two fields would be able to produce in isolation’. To recap, designers have tended to, in the past, produce information lacking scientific rigour. Scientists produce information which is hard to understand, contains equations and lacks practical application.
In regard to all our user groups in this paper, Ralf Herrmann raises the point of ‘when a typeface is read in difficult reading conditions, [...] all those stylistic details that define the overall look of these typeface disappear under difficult reading conditions. What matters most is the skeleton of the letters. On one hand these letter skeletons should be very generic, so they easily match the visual patterns we have learned and seen so many times in our life. But on the other hand, they also need to be somewhat unique. The most generic letter forms do not necessarily create the most legible letters, because too generic letter shapes are harder to differentiate (Hermann, 2009). It is worth noting that generally, letters have become more generic and reliant on a letter’s base skeleton over time (early 1400s blackletter, late 1400s humanist, early 1500s old style, mid 1700s transitional, late 1700s modern, mid 1800s slab serif, and early 1900s sans serif).

Figure 25. From (Hermann, 2009). Top typeface: German road sign font DIN 1451, bottom typeface: Wayfinding Sans Pro. Regarding the ‘a’, the prominent stroke ending on the right may not be necessary to recognize it, but if it is there it helps to distinguish the ‘a’ from other characters. To the right: under difficult reading conditions, details such as the usually rather small crossbars of ‘f’ and ‘t’ get easily lost. Making these parts more prominent can significantly improve the legibility under difficult viewing conditions.
Adhering to the research and guidelines in this paper has clear benefits for the clarity and recognition of letters and symbols in graphic communication. It is positive how designers and researchers are tackling these issues more and more. By including different people’s needs, other than the clients’ and your own, your design will better support the wide range of people who will use your design and ultimately be better.
About the author
Thomas Bohm studied graphic communication design at college (BTEC, Leicester College, UK) and university (BA, Norwich University of the Arts, UK), now works for book publishers and businesses, and continues to run User Design, Illustration and Typesetting a graphic communication design, illustration and production service. Writes, researches and occasionally publishes. Published Punctuation..? (2nd edition, User Design, 2012) a fun and fully illustrated book on punctuation. Has been published in Information Design Journal, Baseline, Slanted, Boxes and Arrows and is a member of the Association of Illustrators and the International Institute for Information Design.
References
- Access Economics. (2009). Future Sight Loss UK 1: Economic Impact of Partial Sight and Blindness in the UK adult population. London: Royal National Institute for the Blind.
- Albert-Jan, P. (14 April, 2009). Re: [ATypI] confusable letter combinations. ATypI member email discussion list, http://www.atypi.org.
- BBC News. (May 23, 2002). Screens blamed for ‘air blunders’. Retrieved May 2010, from http://news.bbc.co.uk/1/hi/uk/2003701.stm.
- Banjanin, B.; Nedeljković, U.; Pinćjer, I. & Puškarević, I. (2013). Legibility based on differentiation of characters: A review of empirical findings fundamental for the type design practice. Journal of Graphic Engineering and Design, Volume 4 (1). Retrieved October 2015, from http://www.grid.uns.ac.rs/jged/download.php?fid=132.
- Beier, S. (2016). Letterform Research: An Academic Orphan. Visible Language 50(2). Retrieved September 2016, from http://visiblelanguagejournal.com/issue/202/article/1372.
- Beier, S, & Larson, K. (2010). Design Improvements for Frequently Misrecognized Letters. Information Design Journal 18(2). Amsterdam: John Benjamins. Website: https://benjamins.com/catalog/idj.18.2.03bei.
- Bigelow, C. (2014). Typography & Dyslexia. Retrieved October 2015, from http://bigelowandholmes.typepad.com/bigelow-holmes/2014/11/typography-dyslexia.html.
- Boer, C. (2008). Dyslexie. Website: http://www.dyslexiefont.com.
- Bright Solutions for Dyslexia. (2010). What is dyslexia? Retrieved October 2010, from https://www.dys-add.com/dyslexia.html.
- Bupa. (March, 2009). Dyslexia. Retrieved October 2010, from http://hcd2.bupa.co.uk/fact_sheets/html/dyslexia.html.
- Burndred, S. (1997). GCSE Mathematics: Intermediate Tier. Cambridge: Pearson Publishing.
- Chaparro, B; Shaikh, A & Chaparro, A. (February, 2006). Examining the Legibility of Two New ClearType Fonts. Vol. 8, Issue 1. Retrieved Oct 2015, from http://www.usabilitynews.org/examining-the-legibility-of-two-new-cleartype-fonts/.
- Chaparro, B. S.; Merkle, E. D.; Fox, D. E. & Chaparro, A. (2011). Examination of the legibility of isolated characters of onscreen typefaces. Information Design Journal 19(1). Amsterdam: John Benjamins. Website: https://benjamins.com/?embed=1#catalog/journals/idj.19.1/toc.
- de Leeuwen, R. (2010). Special font for dyslexia? Master’s thesis, University of Twente, The Netherlands. Retrieved June 2011, from http://www.ilo.gw.utwente.nl/ilo/attachments/032_Masterthesis_Leeuw.pdf.
- DIN. (2013). DIN 1450:2013-04. Retrieved May 2019, from https://www.beuth.de/de/norm/din-1450/170093157.
- Evans, B. J. W. (2004). Visual Factors in Dyslexia. In Turner, M. and Rack, J. (Eds) (2004). The Study of Dyslexia. New York: Kluwer Academic/Plenum.
- Funcke, J. (2002). Excluded by typography? A paper on layout design and presbyopia. MBA Design management assignment. London: University of Westminster.
- Glaab, P. (2017). On quotation marks and other puzzeling punctuation. Retrieved February 2018, from https://www.fontshop.com/content/gansefusschen.
- Grissinger, M. (2017). Misidentification of Alphanumeric Symbols Plays a Role in Errors. Pharmacy and Theraputics. 42(10). Retrieved May 2019, from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5614409/.
- Herrmann, R. (2009). Designing the ultimate wayfinding typeface. Retrieved September 2016, from https://typography.guru/journal/designing-the-ultimate-wayfinding-typeface-r30/.
- Herrmann, R. (2011). What makes letters legible? Retrieved September 2016, from https://typography.guru/journal/what-makes-letters-legible-r37/.
- Hillier, R. (2006). A typeface for the adult dyslexic reader. PhD thesis, Anglia Ruskin University, UK. Retrieved June 2011, from http://www.robsfonts.com/img/uploads/docs/thesis.pdf.
- Hudson, J. (14 April, 2009). Re: [ATypI] confusable letter combinations. ATypI member email discussion list, http://www.atypi.org.
- van Lambalgen, E. (2017). How bad typography (almost) ruined my holiday. Retrieved February 2018, from https://medium.com/@ewoudt/how-bad-typography-almost-ruined-my-holiday-763359569673.
- Nicholson, W. (2007). License Plate Fonts of the Western World: History, Samples, and Download Info. Retrieved May 2010, from http://www.leewardpro.com/articles/licplatefonts/licplate-fonts-eur-2.html.
- Irlen, H. (1991). Reading by the Colours. Overcoming dyslexia and other reading disabilities through the Irlen method. New York: Garden City Park/Avery Pub Group.
- Nini, P. (2006). Typography and the Aging Eye: Typeface Legibility for Older Viewers with Vision Problems. Retrieved October 2010, from http://www.aiga.org/typography-and-the-aging-eye/.
- Office for National Statistics. (2010). Ageing. Retrieved October 2010, from http://www.statistics.gov.uk/cci/nugget.asp?id=949.
- Pennington, B. F. (1991). Diagnosing learning disorders: A neuropsychological framework. New York: Guilford Press.
- Perera, S. (2001). LPfont – An Investigation into the Legibility of Large Print Typefaces. Retrieved August 2016, from http://www.johngilltech.com/reports/lpfont report/.
- Pettengill, B. (2014). Vision Changes: Typography for Aging Audiences. Retrieved September 2016, from http://conversations.marketing-partners.com/2014/11/changing-visiotypography-for-aging-audiences/.
- Poole, A. (2012). Fighting bad typography research. Retrieved September 2016, from http://alexpoole.info/blog/fighting-bad-typography-research/.
- RNIB. (2006). See it Right: Making information accessible for people with sight problems. London: Royal National Institute for the Blind.
- RNIB. (2012). From an email (mixed sources used for the statistic). London: Royal National Institute for the Blind.
- Russell-Minda, E; Jutai, J; Strong, G; Campbell, K; Gold, D; Pretty, L, and Wilmot, L. (2007). The Legibility of Typefaces for Readers with Low Vision: A Research Review. Journal of Visual Impairment & Blindness, 101(7). Retrieved May 2019, from https://eric.ed.gov/?id=EJ772089.
- Sassoon, R. (2001). Through the eyes of a child: perception and type design. In: Jury, D. (ed). Typographic Writing. International Society of Typographic Designers.
- Scarrott, G. (1968). A general purpose type fount suitable for use with optical reading equipment. Penrose Annual, 61. Retrieved May 2010, from http://www.telegraphics.com.au/doc/scarrott_ocrb.pdf.
- Smuc, M.; Windhager, F.; Siebenhandl, K. & Egger, S. (2007). In-Safety: Impaired Visibility Typeface Testing Report. Tern typeface. International Institute for Information Design/European Commission. Retrieved October 2015, from http://luc.devroye.org/IIID-Tern-Study-2009.pdf.
- Shrensky, R. & Sless, D. (2007). Choosing the right method for testing. Retrieved October 2010, from http://www.communication.org.au.
- Spencer, H. (1969). The visible word: problems of legibility. London: Lund Humphries.
- Text Matters. (2001). Typography for visually impaired people. Retrieved October 2010, from http://www.textmatters.com/resources/pdfs/visImpd_typogTM.pdf.
- The Lighthouse Inc. (1995). The Lighthouse National Survey on Vision Loss: The Experience, Attitudes, and Knowledge of Middle-Aged and Older Americans. New York: The Lighthouse Inc.
- The Vision Council. (2015). Vision Loss in America: Aging and Low Vision. 2015 low vision report. Retrieved September 2016, from https://www.thevisioncouncil.org/sites/default/files/VC_LowVision_Report2015.pdf.
- Tiresias. (2009). Visual Impairment. Retrieved August 2016, from http://www.johngilltech.com/guidelines/visual.htm.
- U.S. Census Bureau. (2008). http://www.census.gov/ipc/www/worldhis.html. Washington, US.
- U.S. Census Bureau. (2012). http://www.census.gov. Washington, US.
- Walker, S. (2005). The songs letters sing: typography and children’s reading. National Centre for Language and Literacy. Reading, UK.
- World Health Organisation (WHO). (2001). Table 4 in: WHO World Standard Population Distribution (%), based on world average population between 2000–2025. In: Age Standardization of Rates: A New Who Standard. GPE Discussion Paper Series: No. 31.2. Retrieved October 2015, from http://www.who.int/healthinfo/paper31.pdf.
- World Health Organisation (WHO). (2011). What are the public health implications of global ageing? Online Q&A, 29 September 2011. Retrieved October 2015, from http://www.who.int/features/qa/42/en/index.html.



Recommended Comments
Create an account or sign in to comment