

Search the Community
Showing results for tags 'unicode'.
Found 19 results
-

Unicode 16.0 Alpha Review Opens for Feedback
Ralf Herrmann posted a news entry in Typography Weekly #131
 The repertoire for Unicode Version 16.0 is now open for early review and comment until April 2. As a reminder, during alpha review the repertoire is reasonably mature and stable, but is not yet completely locked down.
The repertoire for Unicode Version 16.0 is now open for early review and comment until April 2. As a reminder, during alpha review the repertoire is reasonably mature and stable, but is not yet completely locked down. -
Did you know that the Unicode Common Locale Data Repository (CLDR) collects, among many other things, typographical terms – mostly axises and styles for variable fonts – in many languages, in order to display them appropriately in localized user interfaces? Many companies rely (often blindly) on this data, few contribute to it (with varying expertise for specialist jargon). If you think the translation for the languages you know could be improved, it’s possible to register an account for the Survey Tool and contribute while it’s open to submissions, but it’s usually simpler to raise an issue at Unicode’s Jira. Axis and Styles `ital`: italic `ital-1`: cursive `opsz`: optical size (in points) `opsz-8`: caption `opsz-12`: text `opsz-18`: titling `opsz-72`: display `opsz-144`: poster `slnt`: slant (in degrees) `slnt--12`: backslanted `slnt-0`: upright `slnt-12`: slanted `slnt-24`: extra-slanted `wdth`: width (percentages), expansion or compression `wdth-50`: ultracondensed `wdth-50-compressed`: ultracompressed `wdth-50-narrow`: ultranarrow `wdth-62.5`: extra-condensed `wdth-62.5-compressed`: extra-compressed `wdth-62.5-narrow`: extra-narrow `wdth-75`: condensed `wdth-75-compressed`: compressed `wdth-75-narrow`: compressed `wdth-87.5`: semicondensed `wdth-87.5-compressed`: semicompressed `wdth-87.5-narrow`: seminarrow `wdth-100`: normal `wdth-112.5`: semiexpanded `wdth-112.5-extended`: semiextended `wdth-112.5-wide`: semiwide `wdth-125`: expanded `wdth-125-extended`: extended `wdth-125-wide`: wide `wdth-150`: extra-expanded `wdth-150-extended`: extra-extended `wdth-150-wide`: extra-wide `wdth-200`: ultraexpanded `wdth-200-extended`: ultraextended `wdth-200-wide`: ultrawide `wght`: weight “boldness” `wght-100`: thin `wght-200`: extra-light `wght-200-ultra`: ultralight `wght-300`: light `wght-350`: semilight `wght-380`: book `wght-400`: regular `wght-500`: medium `wght-600`: semibold `wght-600-demi`: demibold `wght-700`: bold `wght-800`: extra-bold `wght-900`: black `wght-900-heavy`: heavy `wght-950`: extra-black `wght-950-ultrablack`: ultrablack `wght-950-ultraheavy`: ultraheavy Features `afrc`: vertical fractions `cpsp`: capital spacing `dlig`: optional ligatures `frac`: diagonal fractions `lnum`: lining numbers `onum`: old-style figures `ordn`: ordinals `pnum`: proportional numbers `smcp`: small capitals `tnum`: tabular numbers `zero`: slashed zero
-
Announcing The Unicode Standard, Version 15.1
Ralf Herrmann posted a news entry in Typography Weekly #129
 This version adds 627 characters, bringing the total number of characters to 149,813.
This version adds 627 characters, bringing the total number of characters to 149,813. -
 Ever been bit by a Unicode bug? Maybe you weren't treating UTF-8 encoded data correctly, or tried to read it as ASCII? Maybe you mixed up UTF-8 vs UTF-16? Unicode and character encoding might seem like a tricky topic, but let's break them down and learn about them piece by piece, from ASCII to code points to graphemes to combining character modifiers and more.
Ever been bit by a Unicode bug? Maybe you weren't treating UTF-8 encoded data correctly, or tried to read it as ASCII? Maybe you mixed up UTF-8 vs UTF-16? Unicode and character encoding might seem like a tricky topic, but let's break them down and learn about them piece by piece, from ASCII to code points to graphemes to combining character modifiers and more. -
Unicode consortium will no longer accept flag emoji proposals
Ralf Herrmann posted a news entry in Typography Weekly #118
 “The inclusion of new flags will always continue to emphasize the exclusion of others. And there isn’t much room for the fluid nature of politics — countries change but Unicode additions are forever — once a character is added it can never be removed.”
“The inclusion of new flags will always continue to emphasize the exclusion of others. And there isn’t much room for the fluid nature of politics — countries change but Unicode additions are forever — once a character is added it can never be removed.” -
 Unicode 14.0 adds 838 characters, for a total of 144,697 characters. These additions include 5 new scripts, for a total of 159 scripts, as well as 37 new emoji characters.
Unicode 14.0 adds 838 characters, for a total of 144,697 characters. These additions include 5 new scripts, for a total of 159 scripts, as well as 37 new emoji characters. -
An online tool that allows you to draw any shape and tries to match it with the most similar Unicode character it can find.
-
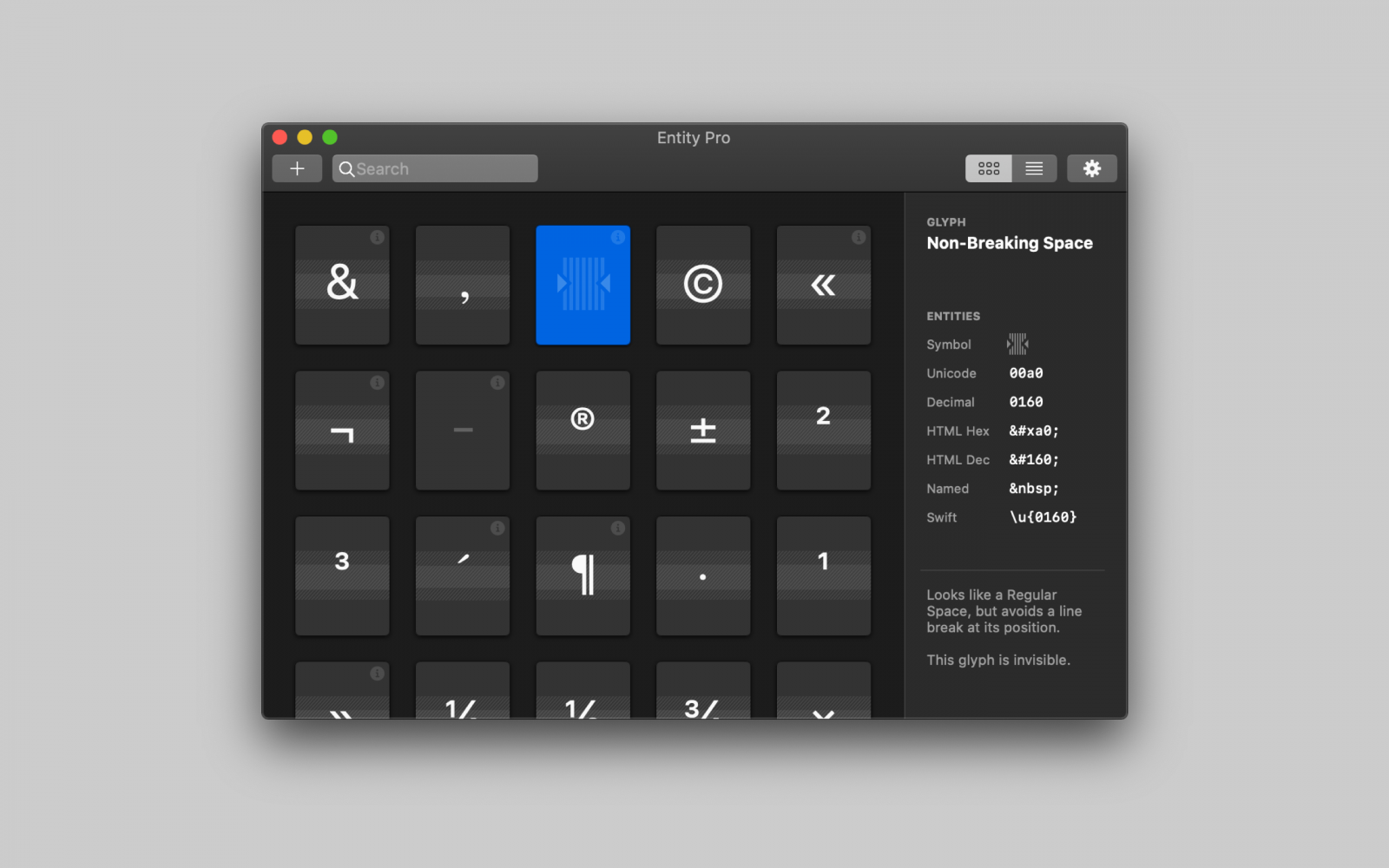 “The ultimate glyph finder app with a passion for digital typography—crafted for digital creators and macOS.”
“The ultimate glyph finder app with a passion for digital typography—crafted for digital creators and macOS.” -
How to find fonts that include specific characters
Ralf Herrmann posted a video in Typography Videos
 When you work with text on a computer, you can easily get into the situation, that you need to use a certain character, but you don’t know which of your fonts support this character. So what do you do? Just try out every font one by one? Well, let’s look at a few ways to do this a little bit more efficiently. From the Typography.Guru YouTube Channel ☞ https://www.youtube.com/c/typographyguru
When you work with text on a computer, you can easily get into the situation, that you need to use a certain character, but you don’t know which of your fonts support this character. So what do you do? Just try out every font one by one? Well, let’s look at a few ways to do this a little bit more efficiently. From the Typography.Guru YouTube Channel ☞ https://www.youtube.com/c/typographyguru -
Apparently, more than a year ago, the Bitcoin sign was added to the Unicode Standard: ₿. The symbol started as a logo, and is arguably rather ugly as a currency sign. But what irks me the most is the use of the capital |B| as a base: B is the symbol for byte, not bit. So, in a bit (!) of speculative glyph design, let’s imagine a world in which it would make sense to add a Bitcoin sign to Unicode, and in which it would be done with some thought. Here are my offerings: They could be seen as the same design in different typeface styles, or variations on the same idea. There is a chance it already exists as an alchemical symbol or IPA extension, and I reckon it has similarities with the newish Russian ruble (₽) and Turkish lira (₺) signs, but I don’t dislike the hint of a |t| in the sans serif variation. So, anyone else would like to engage in some pointless speculative glyph design?

-
This website presents one glyph for each of the world’s writing systems. It is the first step of the Missing Scripts Project, a long-term initiative that aims to identify writing systems which are not yet encoded in the Unicode standard. As of today, there are still 146 scripts not yet encoded in Unicode. Concept: Johannes Bergerhausen, Hochschule Mainz, Germany Research: Dr. Deborah Anderson, Department of Linguistics, UC Berkeley, USA Type Design: Font »BlockDock« by J. Bergerhausen and Jérome Knebusch, 2015—2018 Font »MissingScripts« by J. Bergerhausen, Arthur Francietta and Morgane Pierson at ANRT, Nancy, France, 2016 — 2018 Design: Ilka Helmig, Johannes Bergerhausen, Cologne 2018 Design/Coding/UX: wysiwyg*, Düsseldorf 2018
-
 Johannes Bergerhausen at TEDxVienna Prof. Johannes Bergerhausen born 1965 in Bonn, Germany, studied Communication Design at the University of Applied Sciences in Düsseldorf. From 1993 to 2000, he lived and worked as a designer in Paris. First he collaborated with the Founders of Grapus, Gérard Paris-Clavel and Pierre Bernard, then he founded his own office. In 1998 he was awarded a grant from the French Centre National des Arts Plastiques for a typographic research project on the ASCII-Code. He returned to Germany in 2000 and, since 2002, is Professor of Typography and Book Design at the University of Applied Sciences in Mainz. Lectures in Amiens, Beirut, Berlin, Brussels, Dubai, Frankfurt, London, Malta, Paris, Prague, Rotterdam, San Francisco, Sofia, Weimar. Since 2004, he is working on the decodeunicode.org project, supported by the German Federal Ministry of Education and Research, which went online in 2005. Semester of research 2007 in Paris. He received many design awards like RedDot, Type Directors Club of New York, ADC, iF, Best German Books and more. In 2011, together with Siri Poarangan, he published »decodeunicode — Die Schriftzeichen der Welt«, a repertoire of the world's 109,242 digital characters. In 2012, he was awarded with the Designpreis in Gold of the Federal Republic of Germany. He is currently working on a digital cuneiform font.
Johannes Bergerhausen at TEDxVienna Prof. Johannes Bergerhausen born 1965 in Bonn, Germany, studied Communication Design at the University of Applied Sciences in Düsseldorf. From 1993 to 2000, he lived and worked as a designer in Paris. First he collaborated with the Founders of Grapus, Gérard Paris-Clavel and Pierre Bernard, then he founded his own office. In 1998 he was awarded a grant from the French Centre National des Arts Plastiques for a typographic research project on the ASCII-Code. He returned to Germany in 2000 and, since 2002, is Professor of Typography and Book Design at the University of Applied Sciences in Mainz. Lectures in Amiens, Beirut, Berlin, Brussels, Dubai, Frankfurt, London, Malta, Paris, Prague, Rotterdam, San Francisco, Sofia, Weimar. Since 2004, he is working on the decodeunicode.org project, supported by the German Federal Ministry of Education and Research, which went online in 2005. Semester of research 2007 in Paris. He received many design awards like RedDot, Type Directors Club of New York, ADC, iF, Best German Books and more. In 2011, together with Siri Poarangan, he published »decodeunicode — Die Schriftzeichen der Welt«, a repertoire of the world's 109,242 digital characters. In 2012, he was awarded with the Designpreis in Gold of the Federal Republic of Germany. He is currently working on a digital cuneiform font. -
 Emoji Levels & Presentations With Unicode 6 several hundred code points were added to the Unicode standard to encode the Japanese symbols. But in theory, one could claim, that Unicode never really “encoded Emoji”. Instead, the Unicode consortium encoded regular (symbol) characters, which companies such as Apple and Microsoft just happens to have displayed as full color images in their software. With Unicode 8 this changes. Now the standard makes clear recommendations about whether a symbol should be treated as Emoji or text symbol (i.e. as a one-color symbol that takes on the properties—like color—of the surrounding text). There are also two variation selectors, which can be used to change the default presentation style within a text. If you add them behind a symbol, you can force an Emoji or text output (if supported). U+FE0E VARIATION SELECTOR-15 (VS15) for a text presentation U+FE0F VARIATION SELECTOR-16 (VS16) for an emoji presentation In addition to the presentation style, Unicode 8 now also defines default Emoji sets. “Level 1 Emoji” are those with a broad support among vendors at present. They include over 700 of the original Japanese symbols, as well as additional characters like the ones from the Unicode range “Transportation and Map Symbols”. All other Emoji are “Level 2 Emoji”. They might not have a color representation yet or might be missing completely in current Emoji fonts, but they are supposed to be shown as Emoji in the future. There is now a total of 1281 Emoji in Unicode 8. Typography.Guru has a section named List of Emoji Codes and Meanings dedicated to show the details of every Emoji character. New Emoji in Unicode 8 A total of 41 new Emoji were added to Unicode 8 from these categories: Emoji modifiers U+1F3FB EMOJI MODIFIER FITZPATRICK TYPE-1-2 U+1F3FC EMOJI MODIFIER FITZPATRICK TYPE-3 U+1F3FD EMOJI MODIFIER FITZPATRICK TYPE-4 U+1F3FE EMOJI MODIFIER FITZPATRICK TYPE-5 U+1F3FF EMOJI MODIFIER FITZPATRICK TYPE-6 Faces, Hands, and Zodiac Symbols U+1F910 ZIPPER-MOUTH FACE U+1F911 MONEY-MOUTH FACE U+1F912 FACE WITH THERMOMETER U+1F913 NERD FACE U+1F914 THINKING FACE U+1F644 FACE WITH ROLLING EYES U+1F643 UPSIDE-DOWN FACE U+1F915 FACE WITH HEAD-BANDAGE U+1F916 ROBOT FACE U+1F917 HUGGING FACE U+1F918 SIGN OF THE HORNS U+1F980 CRAB (also Cancer) U+1F982 SCORPION (also Scorpio) U+1F981 LION FACE (also Leo) U+1F3F9 BOW AND ARROW (also Sagittarius) U+1F3FA AMPHORA (also Aquarius) Symbols of Religious Significance U+1F6D0 PLACE OF WORSHIP U+1F54B KAABA U+1F54C MOSQUE U+1F54D SYNAGOGUE U+1F54E MENORAH WITH NINE BRANCHES U+1F4FF PRAYER BEADS Missing Top Sports Symbols U+1F3CF CRICKET BAT AND BALL U+1F3D0 VOLLEYBALL U+1F3D1 FIELD HOCKEY STICK AND BALL U+1F3D2 ICE HOCKEY STICK AND PUCK U+1F3D3 TABLE TENNIS PADDLE AND BALL U+1F3F8 BADMINTON RACQUET AND SHUTTLECOCK Most Popularly Requested Emoji U+1F32D HOT DOG U+1F32E TACO U+1F32F BURRITO U+1F9C0 CHEESE WEDGE U+1F37F POPCORN U+1F37E BOTTLE WITH POPPING CORK U+1F983 TURKEY U+1F984 UNICORN FACE Diversity Symbol characters are meant to be, well, symbolic. They are used to convey a certain meaning, while neglecting all other specifics. For example, the symbol for “woman” might be shown with a skirt and long hair. But that is just meant to help to convey the meaning “woman”, not to limit the meaning to “woman with long hair wearing skirts”. In the same way, the skin color of human Emoji symbols could be understood as one of dozens of such negligible features. And yet, for years people have been asking for Emoji with other skin colors. So Unicode now includes a range of skin color modifiers. These special characters are added behind an Emoji, and if supported, will replace the default Emoji style with one of five representations using a specific skin color. When an Emoji for this combination of default symbol + color variation does not exist, both characters are shown side by side, just as they are encoded within the text. Combined (left) and separated view (right) of human Emoji + skin color modifier 5. With skin colors not being a negligible feature of human Emoji anymore, the default light skin color of existing Emoji sets had to change. Unicode now recommends a non-realistic color such as the yellow (#FFCC22) used for smileys, blue (#3399CC) or grey (#CCCCCC). Apple has already shipped such symbols with their latest iOS and Mac OS releases using a non-realistic yellow skin tone. Microsoft will use grey for their color font Emoji. Multi-person groupings may explicitly indicate gender (like “Man and Woman holding Hands”), others may not (like “family”). In combination with skin colors, such groupings lead to an endless amount of possibilities, which cannot be encoded as individual characters. The solution is therefore: character sequences. When the special character ZERO WIDTH JOINER (U+200D) is put between Emoji, it indicates, that these symbols are meant to be shown as one glyph if possible. Apple’s sets of family and couple Emoji already make use of character sequences. But even with these added options for diversity, the political correctness debates around Unicode Emoji probably won’t stop anytime soon. The more specific the symbols get, the more possibilities arise to miss certain variations or to feel offended by the specific display of existing ones. And so for Unicode 9 there is already a discussion about adding more gender variations such as “Mother Christmas”. As the Unicode Emoji Tech Report correctly notes: “… there are many other types of diversity in human appearance besides different skin tones: Different hair styles and color, use of eyeglasses, various kinds of facial hair, different body shapes, different headwear, and so on. It is beyond the scope of Unicode to provide an encoding-based mechanism for representing every aspect of human appearance diversity that emoji users might want to indicate. The best approach for communicating very specific human images—or any type of image in which preservation of specific appearance is very important—is the use of embedded graphics …” I am certainly curious what the future will hold in this regard. Does Unicode become a museum of things that were relevant for short passages of times (e.g. FAX MACHINE—U+1F4E0, SELFIE—U+1F933)? Or do we move away from this approach and will be able to transmit graphics reliably in a completely different way? Related Links: Typography.Guru List of Emoji Codes & Meanings Unicode Technical Report #51 with all the technical details about Emoji in the latest release of the Unicode standard
Emoji Levels & Presentations With Unicode 6 several hundred code points were added to the Unicode standard to encode the Japanese symbols. But in theory, one could claim, that Unicode never really “encoded Emoji”. Instead, the Unicode consortium encoded regular (symbol) characters, which companies such as Apple and Microsoft just happens to have displayed as full color images in their software. With Unicode 8 this changes. Now the standard makes clear recommendations about whether a symbol should be treated as Emoji or text symbol (i.e. as a one-color symbol that takes on the properties—like color—of the surrounding text). There are also two variation selectors, which can be used to change the default presentation style within a text. If you add them behind a symbol, you can force an Emoji or text output (if supported). U+FE0E VARIATION SELECTOR-15 (VS15) for a text presentation U+FE0F VARIATION SELECTOR-16 (VS16) for an emoji presentation In addition to the presentation style, Unicode 8 now also defines default Emoji sets. “Level 1 Emoji” are those with a broad support among vendors at present. They include over 700 of the original Japanese symbols, as well as additional characters like the ones from the Unicode range “Transportation and Map Symbols”. All other Emoji are “Level 2 Emoji”. They might not have a color representation yet or might be missing completely in current Emoji fonts, but they are supposed to be shown as Emoji in the future. There is now a total of 1281 Emoji in Unicode 8. Typography.Guru has a section named List of Emoji Codes and Meanings dedicated to show the details of every Emoji character. New Emoji in Unicode 8 A total of 41 new Emoji were added to Unicode 8 from these categories: Emoji modifiers U+1F3FB EMOJI MODIFIER FITZPATRICK TYPE-1-2 U+1F3FC EMOJI MODIFIER FITZPATRICK TYPE-3 U+1F3FD EMOJI MODIFIER FITZPATRICK TYPE-4 U+1F3FE EMOJI MODIFIER FITZPATRICK TYPE-5 U+1F3FF EMOJI MODIFIER FITZPATRICK TYPE-6 Faces, Hands, and Zodiac Symbols U+1F910 ZIPPER-MOUTH FACE U+1F911 MONEY-MOUTH FACE U+1F912 FACE WITH THERMOMETER U+1F913 NERD FACE U+1F914 THINKING FACE U+1F644 FACE WITH ROLLING EYES U+1F643 UPSIDE-DOWN FACE U+1F915 FACE WITH HEAD-BANDAGE U+1F916 ROBOT FACE U+1F917 HUGGING FACE U+1F918 SIGN OF THE HORNS U+1F980 CRAB (also Cancer) U+1F982 SCORPION (also Scorpio) U+1F981 LION FACE (also Leo) U+1F3F9 BOW AND ARROW (also Sagittarius) U+1F3FA AMPHORA (also Aquarius) Symbols of Religious Significance U+1F6D0 PLACE OF WORSHIP U+1F54B KAABA U+1F54C MOSQUE U+1F54D SYNAGOGUE U+1F54E MENORAH WITH NINE BRANCHES U+1F4FF PRAYER BEADS Missing Top Sports Symbols U+1F3CF CRICKET BAT AND BALL U+1F3D0 VOLLEYBALL U+1F3D1 FIELD HOCKEY STICK AND BALL U+1F3D2 ICE HOCKEY STICK AND PUCK U+1F3D3 TABLE TENNIS PADDLE AND BALL U+1F3F8 BADMINTON RACQUET AND SHUTTLECOCK Most Popularly Requested Emoji U+1F32D HOT DOG U+1F32E TACO U+1F32F BURRITO U+1F9C0 CHEESE WEDGE U+1F37F POPCORN U+1F37E BOTTLE WITH POPPING CORK U+1F983 TURKEY U+1F984 UNICORN FACE Diversity Symbol characters are meant to be, well, symbolic. They are used to convey a certain meaning, while neglecting all other specifics. For example, the symbol for “woman” might be shown with a skirt and long hair. But that is just meant to help to convey the meaning “woman”, not to limit the meaning to “woman with long hair wearing skirts”. In the same way, the skin color of human Emoji symbols could be understood as one of dozens of such negligible features. And yet, for years people have been asking for Emoji with other skin colors. So Unicode now includes a range of skin color modifiers. These special characters are added behind an Emoji, and if supported, will replace the default Emoji style with one of five representations using a specific skin color. When an Emoji for this combination of default symbol + color variation does not exist, both characters are shown side by side, just as they are encoded within the text. Combined (left) and separated view (right) of human Emoji + skin color modifier 5. With skin colors not being a negligible feature of human Emoji anymore, the default light skin color of existing Emoji sets had to change. Unicode now recommends a non-realistic color such as the yellow (#FFCC22) used for smileys, blue (#3399CC) or grey (#CCCCCC). Apple has already shipped such symbols with their latest iOS and Mac OS releases using a non-realistic yellow skin tone. Microsoft will use grey for their color font Emoji. Multi-person groupings may explicitly indicate gender (like “Man and Woman holding Hands”), others may not (like “family”). In combination with skin colors, such groupings lead to an endless amount of possibilities, which cannot be encoded as individual characters. The solution is therefore: character sequences. When the special character ZERO WIDTH JOINER (U+200D) is put between Emoji, it indicates, that these symbols are meant to be shown as one glyph if possible. Apple’s sets of family and couple Emoji already make use of character sequences. But even with these added options for diversity, the political correctness debates around Unicode Emoji probably won’t stop anytime soon. The more specific the symbols get, the more possibilities arise to miss certain variations or to feel offended by the specific display of existing ones. And so for Unicode 9 there is already a discussion about adding more gender variations such as “Mother Christmas”. As the Unicode Emoji Tech Report correctly notes: “… there are many other types of diversity in human appearance besides different skin tones: Different hair styles and color, use of eyeglasses, various kinds of facial hair, different body shapes, different headwear, and so on. It is beyond the scope of Unicode to provide an encoding-based mechanism for representing every aspect of human appearance diversity that emoji users might want to indicate. The best approach for communicating very specific human images—or any type of image in which preservation of specific appearance is very important—is the use of embedded graphics …” I am certainly curious what the future will hold in this regard. Does Unicode become a museum of things that were relevant for short passages of times (e.g. FAX MACHINE—U+1F4E0, SELFIE—U+1F933)? Or do we move away from this approach and will be able to transmit graphics reliably in a completely different way? Related Links: Typography.Guru List of Emoji Codes & Meanings Unicode Technical Report #51 with all the technical details about Emoji in the latest release of the Unicode standard -
 It all started with 128 ASCII characters in the 1960s. In the 1980s a variety of (largely incompatible) 256 character codepages where used. Finally in the early 1990s a new system was invented that should overcome all the limitations and incompatibilities of the older codepages: Unicode—a system where all character of all writing systems are combined into one standard. It took some time, but today Unicode is the default encoding for basically all electronic communications. It doesn’t matter anymore if you use Windows or Mac OS or which font you use to display a text. I can put any of the 113,021 Unicode 7.0 characters on this website and you could safely copy and paste them to a local file (for example). Because every code point is just used once. There is no ambiguity anymore. A commercial Latin OpenType will probably have a rather complete character set for the first 256 characters, but there can be any number of unencoded characters as well. As an example: Arno Pro from Adobe includes the character sets for Latin, Greek and Cyrillic together using around 1000 glyph slots. But the fonts contain an additional range of around 1800 unencoded glyphs! The basic character set can be accessed directly with the keyboard using the appropriate keyboard layouts. To access Unicode characters that aren’t directly available this way, you can either copy them from certain websites or you can use character map apps for your operating system. Both of these methods are Unicode-based, which makes them a reliable way of accessing any character you want. But what about glyphs that don’t have a Unicode code point in the first place — like stylistic alternates, different figure sets, discretionary ligatures, small caps and certain pictograms? The glyphs in a font can be referenced in different ways. The glyph ID simply represents the position of a glyph in the list of all glyphs. But that isn’t a very reliable way to access a character. With the next update of the font the position of a certain glyph in the font might have changed. There is also no semantic meaning to a certain glyph ID. In one font, the ID 1 might be an A, in the next font it might be a space character. The glyph names on the other hand are used for OpenType functionalities. If you activate the ligature feature the combination of f + b can be replaced by an fb ligature which is accessed through its glyph name, e.g. “f_b”. But again, that is font specific. Another font might not have that ligature or use another glyph name. The only reliable way for users to access the glyph for a specific character regardless of the font or font version is a Unicode value and that is what most character map apps and character map websites offer. Glyphs without a Unicode value are usually simply omitted. To encode or not to encode Type designers need to choose one of two ways to deal with glyphs that don’t have an official Unicode code point: 1. Don’t encode them at all. This is the recommended way from a semantical and technical point of view. A small caps letter is just a visual/stylistic alternative to a lowercase letter. So it is accessed by typing the lowercase letter and then applying a styling, which activates the OpenType feature to switch out the lowercase letter with the small caps letter while retaining the character encoding of the lowercase letter. The replacement rule is set up as an OpenType feature within the font and the small caps character will be accessed only through an arbitrary glyph name, not a standardised Unicode value. The downside of this approach is: The app you are using needs to support the specific OpenType features or these glyphs will be inaccessible. Even though OpenType has been around for many years now, this is still a problem. People buy commercial fonts every day only to find out, that all the advertised ligatures and alternative characters cannot be accessed in their word processor or that their favourite browser cannot show the figure set they would like to use. 2. Use PUA codes Instead of relying on OpenType, glyphs that don’t match an existing Unicode character can also be assigned a Unicode value. For this purpose, Unicode has a so-called Private Use Area (PUA). A type designer can pick any Unicode value from that range and apply it to any glyph where no official Unicode value is available. When this is done, the glyph can appear in character map tools and can then be copied & pasted just like any other character. But when this technique is used, the PUA code point will only work for that specific font. Another font might show a completely different glyph (or nothing at all) and proper indexing or hyphenation will also fail, because these PUA characters have no standardised semantic meaning. So when you are looking for glyphs in a font, that don’t fall in the category of official Unicode characters, you need to check first which of the above methods is used. PUA characters might allow you to access any glyph in any app more easily, but you should keep in mind that their non-sematic encoding can cause problems. If you use PUA codes to access pictograms of a signage font for a vinyl cut you might be fine. But if you want to publish electronic documents which should be indexed, shared or copied, you might want to steer clear of the Private Use Area. To access official Unicode characters and PUA characters, you can try the Windows Character Map or alternative tools like PopChar or BabelMap. On Mac OS X the built in Character Viewer is quite handy, but it does not display font-specific PUA characters. For that, you might want to have a look at Ultra Character Map instead. Working with unencoded characters So how should one deal with unencoded glyphs in OpenType fonts? Unfortunately, there is no single app or no single trick, which makes them easily accessible across all apps on your operating system. But here are some recommendations which might be helpful to you. Know your type—study the “manual” When you buy a font, look out for the type specimen PDF and save it with the font. It might not always be easy to find, especially on reseller sites. So visit the designer’s or foundry’s site if necessary. The type specimen PDF will in most cases not only show the full glyph set, but also list the OpenType features to reach unencoded glyphs. You understand the possibilities of specific OpenType fonts much easier this way than by clicking through the OpenType menu of your app. This type specimen PDF from Typejockeys explains the OpenType features of Ingeborg Create your own glyph sheets if needed There is a nice free tool for Adobe InDesign called Font Table, which can generate an overview of all glyphs in a font. It just tries to access every possible glyph ID and so you get a full overview, which does not rely on Unicode code points. You can then save this glyph table as PDF or print it out. The glyph table of Arno Pro made in InDesign with Font Table Copy Glyph IDs across supported apps (Mac OS only) It isn’t heavily advertised because it doesn’t work across all apps, but Mac OS X actually allows you to copy & paste unencoded glyphs through their glyph ID. But it only works if both apps you are using support this. In FontBook, switch to the Repertoire view (⌘+2) and the just select and copy the character. You can then paste it to TextEdit for example or some other apps that use Apples text engine. If you use FontExplorer X as font manager you can also copy unencoded glyphs from the info panel of a specific font. And if you want to use this technique frequently you might want to take a look at Ultra Character Map. Accessing all those deliberately unencoded ligatures of Canapé? FontExplorer can help you. Using the Glyphs Panel (InDesign/Illustrator) If you use Adobe InDesign or Adobe Illustrator it’s very easy to work with unencoded glyphs. Not only do these apps provide a full glyph map, but you can also easily access glyph alternatives or filter the selection to only show the glyph replacements for certain OpenType features. Click on the triangles in the glyphs panel of InDesign or Illustrator to show alternative glyphs which will likely not be directly accessible through Unicode values. Find you special glyphs easily with the filter menu and double-click on the glyphs to add them to your text. The Photoshop trick While InDesign and Illustrator have a glyphs panel, Photoshop until the current version (CC 2014) does not and the options to activate OpenType features are also extremely limited. So even the unencoded glyphs of many of Adobe’s own Pro fonts might simply be unaccessible in Photoshop. But there is a trick! Photoshop allows you to copy unencoded glyphs from one app — and one app only: Illustrator. Create your text in Illustrator and apply OpenType features or select specific glyphs from glyphs panel. Select the text and copy it. Go to Photoshop and paste the text while the text tool is active. Photoshop will paste the text and maintain all glyphs. First line: Photoshop default. Second line: Pasted, but still editable text from Illustrator.
It all started with 128 ASCII characters in the 1960s. In the 1980s a variety of (largely incompatible) 256 character codepages where used. Finally in the early 1990s a new system was invented that should overcome all the limitations and incompatibilities of the older codepages: Unicode—a system where all character of all writing systems are combined into one standard. It took some time, but today Unicode is the default encoding for basically all electronic communications. It doesn’t matter anymore if you use Windows or Mac OS or which font you use to display a text. I can put any of the 113,021 Unicode 7.0 characters on this website and you could safely copy and paste them to a local file (for example). Because every code point is just used once. There is no ambiguity anymore. A commercial Latin OpenType will probably have a rather complete character set for the first 256 characters, but there can be any number of unencoded characters as well. As an example: Arno Pro from Adobe includes the character sets for Latin, Greek and Cyrillic together using around 1000 glyph slots. But the fonts contain an additional range of around 1800 unencoded glyphs! The basic character set can be accessed directly with the keyboard using the appropriate keyboard layouts. To access Unicode characters that aren’t directly available this way, you can either copy them from certain websites or you can use character map apps for your operating system. Both of these methods are Unicode-based, which makes them a reliable way of accessing any character you want. But what about glyphs that don’t have a Unicode code point in the first place — like stylistic alternates, different figure sets, discretionary ligatures, small caps and certain pictograms? The glyphs in a font can be referenced in different ways. The glyph ID simply represents the position of a glyph in the list of all glyphs. But that isn’t a very reliable way to access a character. With the next update of the font the position of a certain glyph in the font might have changed. There is also no semantic meaning to a certain glyph ID. In one font, the ID 1 might be an A, in the next font it might be a space character. The glyph names on the other hand are used for OpenType functionalities. If you activate the ligature feature the combination of f + b can be replaced by an fb ligature which is accessed through its glyph name, e.g. “f_b”. But again, that is font specific. Another font might not have that ligature or use another glyph name. The only reliable way for users to access the glyph for a specific character regardless of the font or font version is a Unicode value and that is what most character map apps and character map websites offer. Glyphs without a Unicode value are usually simply omitted. To encode or not to encode Type designers need to choose one of two ways to deal with glyphs that don’t have an official Unicode code point: 1. Don’t encode them at all. This is the recommended way from a semantical and technical point of view. A small caps letter is just a visual/stylistic alternative to a lowercase letter. So it is accessed by typing the lowercase letter and then applying a styling, which activates the OpenType feature to switch out the lowercase letter with the small caps letter while retaining the character encoding of the lowercase letter. The replacement rule is set up as an OpenType feature within the font and the small caps character will be accessed only through an arbitrary glyph name, not a standardised Unicode value. The downside of this approach is: The app you are using needs to support the specific OpenType features or these glyphs will be inaccessible. Even though OpenType has been around for many years now, this is still a problem. People buy commercial fonts every day only to find out, that all the advertised ligatures and alternative characters cannot be accessed in their word processor or that their favourite browser cannot show the figure set they would like to use. 2. Use PUA codes Instead of relying on OpenType, glyphs that don’t match an existing Unicode character can also be assigned a Unicode value. For this purpose, Unicode has a so-called Private Use Area (PUA). A type designer can pick any Unicode value from that range and apply it to any glyph where no official Unicode value is available. When this is done, the glyph can appear in character map tools and can then be copied & pasted just like any other character. But when this technique is used, the PUA code point will only work for that specific font. Another font might show a completely different glyph (or nothing at all) and proper indexing or hyphenation will also fail, because these PUA characters have no standardised semantic meaning. So when you are looking for glyphs in a font, that don’t fall in the category of official Unicode characters, you need to check first which of the above methods is used. PUA characters might allow you to access any glyph in any app more easily, but you should keep in mind that their non-sematic encoding can cause problems. If you use PUA codes to access pictograms of a signage font for a vinyl cut you might be fine. But if you want to publish electronic documents which should be indexed, shared or copied, you might want to steer clear of the Private Use Area. To access official Unicode characters and PUA characters, you can try the Windows Character Map or alternative tools like PopChar or BabelMap. On Mac OS X the built in Character Viewer is quite handy, but it does not display font-specific PUA characters. For that, you might want to have a look at Ultra Character Map instead. Working with unencoded characters So how should one deal with unencoded glyphs in OpenType fonts? Unfortunately, there is no single app or no single trick, which makes them easily accessible across all apps on your operating system. But here are some recommendations which might be helpful to you. Know your type—study the “manual” When you buy a font, look out for the type specimen PDF and save it with the font. It might not always be easy to find, especially on reseller sites. So visit the designer’s or foundry’s site if necessary. The type specimen PDF will in most cases not only show the full glyph set, but also list the OpenType features to reach unencoded glyphs. You understand the possibilities of specific OpenType fonts much easier this way than by clicking through the OpenType menu of your app. This type specimen PDF from Typejockeys explains the OpenType features of Ingeborg Create your own glyph sheets if needed There is a nice free tool for Adobe InDesign called Font Table, which can generate an overview of all glyphs in a font. It just tries to access every possible glyph ID and so you get a full overview, which does not rely on Unicode code points. You can then save this glyph table as PDF or print it out. The glyph table of Arno Pro made in InDesign with Font Table Copy Glyph IDs across supported apps (Mac OS only) It isn’t heavily advertised because it doesn’t work across all apps, but Mac OS X actually allows you to copy & paste unencoded glyphs through their glyph ID. But it only works if both apps you are using support this. In FontBook, switch to the Repertoire view (⌘+2) and the just select and copy the character. You can then paste it to TextEdit for example or some other apps that use Apples text engine. If you use FontExplorer X as font manager you can also copy unencoded glyphs from the info panel of a specific font. And if you want to use this technique frequently you might want to take a look at Ultra Character Map. Accessing all those deliberately unencoded ligatures of Canapé? FontExplorer can help you. Using the Glyphs Panel (InDesign/Illustrator) If you use Adobe InDesign or Adobe Illustrator it’s very easy to work with unencoded glyphs. Not only do these apps provide a full glyph map, but you can also easily access glyph alternatives or filter the selection to only show the glyph replacements for certain OpenType features. Click on the triangles in the glyphs panel of InDesign or Illustrator to show alternative glyphs which will likely not be directly accessible through Unicode values. Find you special glyphs easily with the filter menu and double-click on the glyphs to add them to your text. The Photoshop trick While InDesign and Illustrator have a glyphs panel, Photoshop until the current version (CC 2014) does not and the options to activate OpenType features are also extremely limited. So even the unencoded glyphs of many of Adobe’s own Pro fonts might simply be unaccessible in Photoshop. But there is a trick! Photoshop allows you to copy unencoded glyphs from one app — and one app only: Illustrator. Create your text in Illustrator and apply OpenType features or select specific glyphs from glyphs panel. Select the text and copy it. Go to Photoshop and paste the text while the text tool is active. Photoshop will paste the text and maintain all glyphs. First line: Photoshop default. Second line: Pasted, but still editable text from Illustrator.- 1 comment
-
- 1
-

-
- character map
- encoding
- (and 2 more)
-
 Unicode is changing, adding tons more icons and smilies. But what's new and why? Tom Scott takes us through the improvements.
Unicode is changing, adding tons more icons and smilies. But what's new and why? Tom Scott takes us through the improvements. -
 Tom Scott explains how and why we moved from ASCII to Unicode and why UTF8 has become the dominant standard to encode Unicode texts.
Tom Scott explains how and why we moved from ASCII to Unicode and why UTF8 has become the dominant standard to encode Unicode texts. -
Ultra Character Map lets you access any character or glyph in any font and use it in other apps. It also lets you do side-by-side font comparisons, print font catalogs, view detailed character and font information (including the keystroke combinations that produce special or accented characters). Main Features: Access any character, symbol or glyph in any font and use it in your documents. Create your own clip art by applying colors and 3D effects to any character, symbol or glyph. Ultra Character Map gives you access to all Emoji characters available in OS X. Enter text once, then simply scroll through a list to see a preview in every font. Don't want to look at all your fonts? You can filter the list by style, classification, collection or name. Ultra Character Map lets you preview header or paragraph text and includes preset samples to save you even more time. Print font catalogs and font samples. Ultra Character Map lets you print custom font catalogs, font samples and character maps or save them as PDF documents. Ultra Character Map shows all the glyphs in your fonts (even glyphs that are not associated with a character) and lets you view Bézier curves and copy them to other apps. It also features an HTML entity palette, a Unicode 6.1 grid and panels that display extensive character and font information.
-
BabelMap is a free character map application for Windows that allows you to browse through the entire Unicode character repertoire, or search for a particular character by name or by code point. Characters can then be copied to the clipboard for use in any Unicode-aware application. It also provides many useful features and special utilities, as described below. An online-version is available here: http://www.babelstone.co.uk/Unicode/babelmap.html
-
Exploration Unicode number and UTF encodings for each codepoint Related codepoints and decomposition Browsing by plane, codepoint number or character block Unihan data such as definitions, variants, pronunciations and older encodings for many Asian codepoints Finding code points by name or their Unihan definition Finding codepoints via Spotlight Conversion To and from: HTML, CSS, URLs, IDNA and various programming languages Unicode Normalisation with an indication whether the string is already normalised (NFC, NFKC, NFD and NFKD) Split Up and Diff tools to analyse a string codepoint by codepoint and highlight the differences Most of the features are available to all applications you use via the ‘Services’ menu and AppleScript.





